Following the release of Sora 2 two days ago, Sam Altman has become widely recognized due to his frequent appearances in popular social media videos.
| In Shanghai | In Acient China | Talks to a random person |
|---|---|---|
 |
 |
 |
Sora 2 are gaining popularity; however, detailed public documentation regarding their underlying training methodologies remains scarce. OpenAI simply noted that Sora takes inspiration from large language models (LLMs) that acquire generalist capabilities by training on “internet-scale data. It is possible that OpenAI may have scraped YouTube content without permission from Google. On the other hand, Google’s Veo is assumed to benefit from YouTube’s high-quality video. The implication is clear: the ability to generate realistic video is directly proportional to access to petabytes of high-quality, varied footage.
In contrast to these guarded, commercial efforts, open research and published technical reports offer valuable insights into the necessary ingredients for high-quality video generation. For instance, detailed data curation and scaling strategies are explored in foundational models such as:
- Movie Gen: A Cast of Media Foundation Models (https://arxiv.org/abs/2410.13720) on Feb 2025 from Meta.
- HunyuanVideo: A Systematic Framework For Large Video Generative Models (https://arxiv.org/abs/2412.03603) on March 2025 from Tencent.
In this article, we deep dive on the data collections according to the two paper above.
Movie Gen
Our pre-training dataset consists of O(100)M video-text pairs and O(1)B image-text pairs.
Our original pool of data consists of videos that are 4 seconds to 2 minutes long, spanning concepts from different domains such as humans, nature, animals, and objects. Our data curation pipeline yields our final pre-training set of clip-prompt pairs, where each clip is 4s – 16s long, with single-shot camera and non-trivial motion. Our data curation pipeline consists of three filtering stages: 1) visual filtering, 2) motion filtering, and 3) content filtering, and one captioning stage. The filtered clips are annotated with detailed generated captions containing 100 words on average.
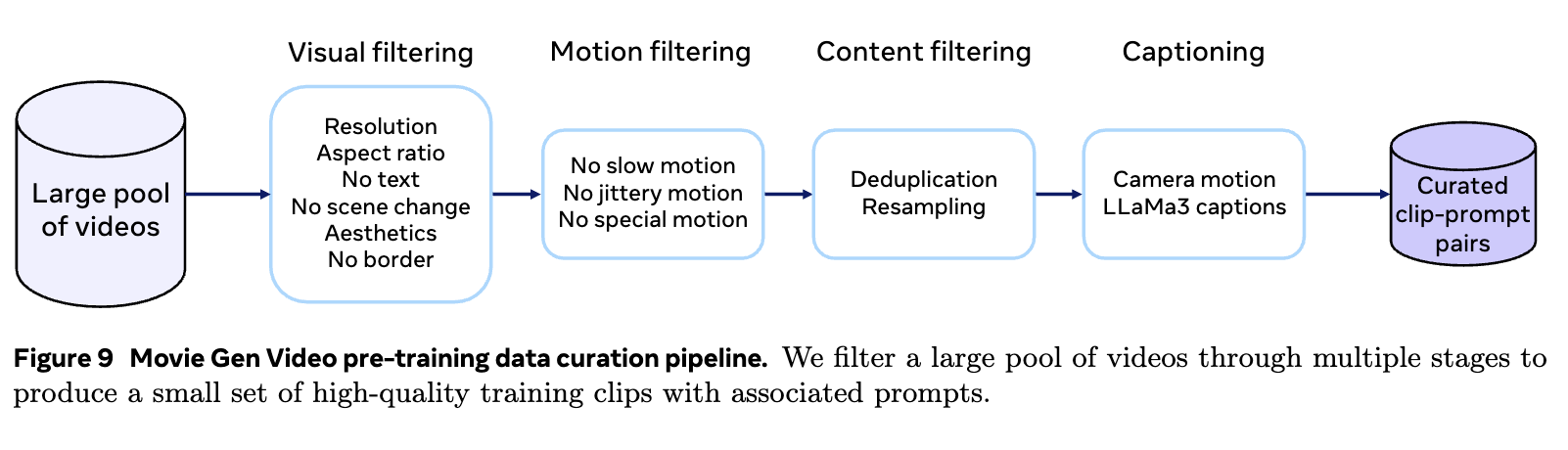
One more interesting step mentioned is “Multi-stage data curation”, likely due to the intuition of curriculumn learning from easy to hard.
We curate 3 subsets of pre-training data with progressively stricter visual, motion, and content thresholds to meet the needs of different stages of pre-training. First, we curated a set of video clips with a minimum width and height of 720 px for low-resolution training. Next, we filtered the set to provide videos with a minimum width and height of 768 px for high-resolution training. Finally, we curated new videos augmenting our high-resolution training set. Our high resolution set has 80% landscape and 20% portrait videos, with at least 60% of them containing humans.
Another small finetuning high-quality and manually curated dataset was created, with the goal to improve the video generation quality. Instead of training one model, multiple models will be produced via fine tuning to form the final model with “ensemble” like technique. The extensive manual labor required for cinematic quality control highlights a fundamental, and often debated, trade-off between human oversight and automated scalability in data curation.
HunyuanVideo
To curate the pretraining data, HunyuanVideo follows a similar workflow.

Similarly, HunyunVideo curate the multi-stage dataset to support multi-stage training from easy to hard, and they also manually curate a high-quality finetuning dataset to further improve model quality.
Our hierarchical data filtering pipeline for video data yields five training datasets, corresponding to the five training stages
we build a fine-tuning dataset comprising ∼1M samples. This dataset is meticulously curated through human annotation.
Conclusion
Ultimately, the power of modern video generation hinges on massive, hyper-detailed datasets. The path forward requires resolving the core tension between the models’ need for near-infinite real-world data and the legal and ethical frameworks restricting its free use. Leveraging real-life data streams captured by emerging technologies like smart glasses presents one potential solution for continuously feeding the AI’s “world simulator.”
References
*This article is inspired by Mu Li’s YouTube talk.